
Table des matières
Un chantier en soi : miner les versions numériques des publications du Québec
Des échanges avec Christian Roy et Gilles Herman, qui développent le projet TAMIS (tamis.ca), ont permis d'identifier une façon de plonger plus avant dans les mentions textuelles des rivières. Il s'agit d'un outil d'analyse de très grands ensembles textuels (des livres en version numérique) qui permet de repérer les occurrences de mots ou d'entités (ici, les rivières qui nous intéressent). L'outil peut aussi bien être utilisé pour des livres de littérature que des livres d'histoire ou des documents administratifs.
Trois principales variables sont à prendre en considération.
Accès
Il faut pouvoir avoir accès aux versions numériques des livres publiés au Québec. Les entrepôts numériques de livres sont potentiellement une mine d'or, plusieurs éditeurs ayant rendu disponibles leur production de cette façon – du moins la production récente. Cependant, pour utiliser ces contenus, il faut avoir l'autorisation de miner ces contenus, de les analyser. Une entente peut être établie avec les éditeurs visés, de sorte de baliser le type d'usage qui est envisagé. Une fois ces ententes passées, la manipulation de ces textes reste somme toute assez aisée (le volume n'est pas disproportionné).
Identification
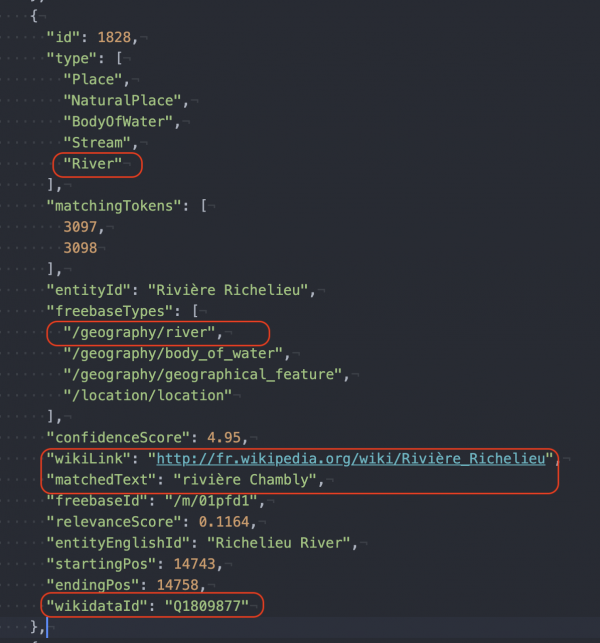
Pour assurer à des résultats intéressants, il faut assurer une identification précise des éléments que l'on recherche. Il ne suffit pas d'avoir une liste des hydronymes recherchés, il faut idéalement pouvoir s'appuyer sur un identifiant stable (comme ceux de Wikidata). L'enjeu reste les appellations redondantes : le mot « Beauport » renvoie indistinctement, dans une recherche textuelle, à un quartier, à des paroisses, à une rivière, à des institutions où figure ce mot. Wikidata peut servir à identifier le référent précis : non pas la rivière dans les Laurentides, mais celle dans la région de Québec.
Toutes les rivières, tous les ruisseaux ne sont pas référencés, ce qui complique les choses évidemment. Il faut pouvoir discriminer les occurrences (Saint-Charles, c'est la rivière ou l'église ?) pour que l'analyse automatisée des textes ne rende pas des tonnes de résultats non pertinents.
Traitement
TAMIS travaille à partir d'un algorithme d'analyse de grands ensembles textuels. Il reste toutefois plusieurs considérations à prendre en compte :
- ententes avec les éditeurs et frais de licence à absorber ;
- intégration des sources (les livres numériques) dans la base de textes à analyser ;
- frais d'utilisation du logiciel ;
- traitement des résultats générés (traitement relativement manuel : évaluation au cas par cas de l'intérêt des occurrences relevées) ;
- d'éventuels développements d'outils pour faciliter le nettoyage des résultats d'analyse.
C'est une avenue très prometteuse, qui supposerait un certain investissement mais qui ouvrirait à des résultats d'occurrences des rivières beaucoup plus variés et non repérables autrement.